Computational Data Science
CMPT 353, Spring 2025
Steven Bergner
This Course
It's Computational Data Science
. We'll come back to what that is.
Course web site: in CourSys, https://coursys.sfu.ca/2025sp-cmpt-353-d1/pages/ .
Course Offering Strategy
In-person instruction with remote access.
- Don't remove material; don't add material.
- Keep what can be done online.
- Encourage in-class participation as best possible.
- Lecture in-person.
- Lab has optional zoom TA access.
Course Offering Strategy
Live lectures will be audio-recorded.
After the lecture time, they will be available as a sound recordings.
Course Offering Strategy
Technology choices:
- Recordings: mp3.
- Discussion forum: CourSys.
- Office hours by video chat: Zoom (or ask in forum).
Course Offering Strategy
Requirements for you:
- A PC with a webcam.
- … that is powerful enough to run a VM: at least 8 GB memory, 20 GB disk, reasonably decent processor (not too old, not a Celeron or other low-spec).
- Windows, Mac, Linux all good.
- A stable Internet connection.
- Participation during lecture time for quizzes.
Grades
- Weekly exercises: 12 × 3.5% = 42%
- Project: 32%
- Quizzes: 4 × 5% = 20%
- Final quiz: 6%
Exercises
Due Thursdays. My goal: make sure you actually try out the things we have talked about and see the reality of applying them.
Will contain some short problems to get you used to the tools, expanding to something a more interesting real
problem.
Project
In the lectures/exercises, we explore what we consider the core
of data science.
The project will let you integrate those techniques, and explore ideas on the edges of that, depending what interests you.
Project
I will (hope to?) post project topic options related to topics like…
- natural language processing
- image recognition
- signal processing
Or if you have something else in mind, we can discuss it.
Project
A few details:
- Groups of 2–3 (or something else?).
- Take the given problem. Use the techniques from the course, and explore others to sensibly attack the problem.
- In a report, summarize your methods, findings, and what worked/didn't.
Quizzes/Exam
Quizzes: 5% each. Dates may change if necessary, but planned during lecture times:
- February 6 (Thursday of week 5)
- February 27 (Thursday of week 8)
- March 20 (Thursday of week 11)
- April 3 (Thursday of week 13)
Final Quiz: April 8 (last day of class for this course)
Us
Instructor: Steven Bergner <sbergner@sfu.ca>.
In lab Office hour: Tuesday 13:30–14:20 in CSIL lab ASB 9840.
Us
TAs:
- Wanying Tian
- Maria Taktasheva
- Mengdi Jin
Office hours: TBD
Lectures and Labs
Thursday noon: lectures
.
Tuesday early afternoon: The TAs and I will all be available for consultation during the lecture time in discussion forum and video chat, mostly for the weekly exercises.
References
Textbooks: none.
Possible reference material:
- Python Data Science Handbook [SFU library]. Also on Github. Good overview of Python, Pandas, matplotlib, Scikit-Learn.
- Python for Data Analysis [SFU library]. Intro to data science workflow, focussing on Python tools.
References
Possible reference material (continued):
- Data Science from Scratch [SFU library]. Building data science tools from scratch so you can see the details.
- Think Like a Data Scientist [SFU library]. Overview of approaching data science problems.
- Additional links to be provided on course web site.
Programming
Python 3 will be the primary programming language language used in the course. If you aren't comfortable with it, you need to be (very) soon.
StackExchange Data Science tags (as of Sep 2021):
| Language | Tagged Qs (Apr'21) | Tagged Qs (Sep'21) | Change (Apr-Sep) |
|---|---|---|---|
| Python | 5217 | 5631 | +7.9% |
| R | 1287 | 1338 | +4.0% |
| Matlab | 148 | 153 | +3.4% |
| Java | 51 | 51 | |
| Scala | 43 | 47 | +9.3% |
Programming
This will be a programming-heavy course. If you don't really like programming, this might not be the course for you.
The programming style will be very library-heavy, which is realistic in the modern world. We will use many libraries: NumPy, Pandas, matplotlib, scikit-learn, statsmodels, ….
Programming
That means you'll spend a lot of time reading the docs and fighting to make the tools do what you want them to, and less implementing the logic yourself. That's also realistic.
The code you would have written would almost certainly have been slower and worse.
Expectations
To get credit for this course, I expect you to demonstrate that you know how to use programming techniques to manipulate and analyse data. That means:
- A pass on the weighted average of the stuff where you demonstrate programming ability: exercises + project.
- A pass on the weighted average of the quizzes.
Failure to do these may result in failing the course.
Expectations
Academic Honesty: it's important, as always.
If you're using an online source, leave a comment.
def this_function(p1, p2):
# adapted from http://stackoverflow.com/a/21623206/1236542
...
That's all I ask, but remember to do it.
Expectations
You are expected to do the work in this course yourself (or as a group for the project).
Independent work is not copying a solution from somewhere but understanding it. If you work with another student, we shouldn't be able to tell from the results.
More details on course web site.
Expectations
The quizzes are structured as regular tests: individual work, but open book.
It will be hard to monitor that, but cheating on our quizzes will be treated as equivalent to cheating on an in-person exam, with corresponding penalties: I will be asking for a grade of FD in the course for any academic dishonesty on quizzes.
Computational Data Science?
Computational Data Science
: data science, but with computation as the focus.
But what is data science?
Data Science?
According to Wikipedia: an interdisciplinary field about processes and systems to extract knowledge or insights from data in various forms…
According to Pat Hanrahan, Tableau Software: [The combination of] business knowledge, analytical skills, and computer science.
According to Daniel Tunkelang, LinkedIn: [The ability to] obtain, scrub, explore, model and interpret data, blending hacking, statistics and machine learning.
Data Science?
According to Joel Grus: There's a joke that says a data scientist is someone who knows more statistics than a computer scientist and more computer science than a statistician.… We'll says that a data scientist is someone who extracts insights from messy data.
Data Science?
According to Drew Conway, Alluvium:
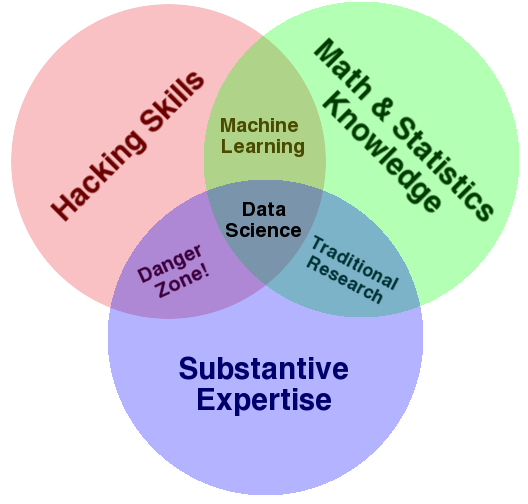
Data Science?
Our definitions:
- Data Science
- You get some data. Then what do you do to get answers from it? Whatever that is, that's data science.
- Computational Data Science
- You get some data. You know how to program. Then what do you do?
Why Data Science?
Why is data science
suddenly so popular?
There's more data being collected: web access logs, purchase history, click-through rates, location history, sensor data, ….
Sometimes the volume of data is big: too big to manage easily. That's where big data
starts.
Why Data Science?
People want answers/insights from that data: Is the marketing campaign working? Is the UI actually usable? What if we did X instead of Y?
New techniques: Machine learning lets us attack questions that were previously unanswerable. Computer scientists are realizing that statistics is important; statisticians are realizing that computer science is important.
Topics (1)
- Data science: what is it? How does data become useful?
- Data processing tools: Python + NumPy + Pandas; analysis tools in Python.
- Data aquisition. Or
where do we find data?
- Getting data into shape: cleaning; extract/transform/load.
Topics (2)
- Making sense of data: statistics. Or
it turns out that stats course was useful
. - Making sense of data: machine learning. Or
it's like AI, except it works
. - Data analysis strategies.
Topics (3)
- Big data tools: Apache Spark and a compute cluster.
- Data visualization and communicating results.